In the last post, I briefly went over the process of reverse engineering the algorithm behind an anti-code generator for an alarm system.
It turned out that the algorithm was very simple indeed. For a given 5-digit numeric quote code, we can derive a 5-digit reset code using a “secret” 8-bit (256 possibilities) version number as a key. This has a lot in common with a keyed hash function or a message authentication code.
There are some pretty serious security implications with this mechanism.
5 digit numeric codes are never going to be strong
Even if I had to enter a pin at random, a 5-digit numeric code only has 100,000 options – I have a 1/100,000 chance of getting it right.
If we made this into a 5-digit hexadecimal code, we would now have a 1/1,048,576 chance – a factor of over 10 times less likely.
Up this to a 6-digit alphanumeric code, and it is now 1/2,176,782,336 – a factor of over 20,000 times less likely we could guess the code.
It doesn’t take many alterations to the limits on codes to make them much more secure.
For this reason it surprises me that alarms are still using 4-digit pins, but most internet forums insist on 8-character passwords with alphanumeric characters and punctuation.
The algorithm isn’t going to stay secret
There is no way to reliably protect a computer application from reverse engineering. If you can run it, at all, it is highly likely the operation can be observed and reversed. Relying on the secrecy of an algorithm or a key hidden within the software is not going to afford any level of security.
One we know the algorithm, the odds massively improve for an attacker
The algorithm takes a version number from 0-255. For a given quote code, I can try each version number, giving me a list of up to 256 potentially valid reset codes (sometimes, two version numbers will generate the same reset code).
If I enter a code from this list, I now have a 1/256 chance of getting it right. Not great compared to 1/100,000 for a purely random guess.
This is entirely due to the short version number used.
Given a quote/reset code, most of the time we can infer the version
It quickly became apparent that for most quote/reset pairs, there was only a single version number than could produce this pair. I’m awful at probability and decision maths, so I thought running a simulation would be better.
I like running simulations – generally when the number of simulations becomes large enough, the results tend towards the correct value. So I tried the following:
1. Generate a genuine quote/reset pair using a random quote.
2. Use a brute force method to see which version numbers can produce this pair
3. Record if more than one version number can produce this quote/reset pair.
I started doing this exhaustively. This would take a long time though… someone on the Crypto stack exchange answered my question with a neater, random simulation.
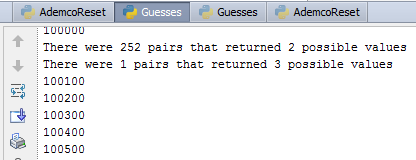
I ran this test over 20 million times. From this it turns out that 99.75% of quote/reset code pairs will directly tell me the version number. Most of the remaining 0.25% require yield two version numbers. A tiny number (<0.001%) yield more than four version numbers. You are almost certain to know the version number after two quote/reset pairs as a result.
What does this mean in the real world?
The version number is treated as the secret, and I am informed that this secret is often constant across an entire alarm company. All ADT alarms or all Modern Security Systems alarms may use the same version number to generate reset codes.
This means I could get hold of any quote/reset pair, infer the version number, and then use that later to generate my own anti-codes for any ADT alarm. I could get hold of these quote/reset pairs by going to an accomplice’s house with a ADT alarm system, or by eavesdropping on communications.
With that anti-code I could either reset a system presenting a quote code, or impersonate an alarm receiving centre (there are other speech based challenge-response requirements here to prove the caller is genuine, which are easily gamed I would imagine).
Conclusion
A 5-digit reset code using an 8-bit key is never going to be secure.
When computer passwords are 8 characters and 128-bit keys are the norm, this anti-code mechanism seems woefully inadequate.












{kind=link}